Lopez Leonardo
- Enunciado
- Fase 1: Planteamiento del problema
- Fase 2: Carga de datos
- Fase 3: Estudio de datos
- Fase 4: Estudio y comparación de algoritmos de clasificación:
- Fase 5: Análisis de resultados obtenidos
Enunciado
El Ayuntamiento de Madrid ha publicado los datos de 2018 referentes a la flota de taxis de la ciudad, y cuenta con más de 15.000 vehículos. Cada licencia puede tener adscrito un único vehículo para la prestación del servicio. Este conjunto de datos se ofrece en un fichero junto con los datos históricos de la flota de taxi indicando para cada vehículo, su matrícula, marca, modelo, combustible, potencia, número de plazas, etc. El campo Fecha indica la fecha en que se realizó la extracción de la flota mensual.
Para este Ayuntamiento construyo un algoritmo en R que clasifique medioambientalmente dicha flota según su grado de contaminación. Para simplificar dicho trabajo, la contaminación se medirá a partir del tipo de combustible, y la Fecha de Matriculación (Año).
Fase 1: Planteamiento del problema
A modo introductorio para concientización, podemos reflexionar con el siguiente video de solo 5 minutos que explica los efectos graves en la salud:
Planteamiento del problema en forma visual:
Fase 2: Carga de datos
rm(list = ls()) # Comienzo limpiando la memoria
# Luego instalo paquetes y llamo las librerías necesarias
#------------------------------------------------------------------------------
#install.packages("caTools")
library(caTools) # Permite partir el conjunto de datos ## Warning: package 'caTools' was built under R version 4.0.5#install.packages("e1071")
library(e1071) # Cargo la librería que utiliza el SVM## Warning: package 'e1071' was built under R version 4.0.5#install.packages("dplyr")
library(dplyr) #Proporciona "gramática" para manipulación y operaciones con data frames## Warning: package 'dplyr' was built under R version 4.0.5##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union#install.packages("rpart")
library(rpart) # Libreria para el árbol de decision## Warning: package 'rpart' was built under R version 4.0.5#install.packages("rpart.plot")
library(rpart.plot) # Libreria para visualizar el árbol de decisión## Warning: package 'rpart.plot' was built under R version 4.0.5#install.packages("randomForest")
library(randomForest) # Librería para Random Forest## Warning: package 'randomForest' was built under R version 4.0.5## randomForest 4.6-14## Type rfNews() to see new features/changes/bug fixes.##
## Attaching package: 'randomForest'## The following object is masked from 'package:dplyr':
##
## combine#install.packages("party")
library(party) # Librería para visualizar el árbol## Warning: package 'party' was built under R version 4.0.5## Loading required package: grid## Loading required package: mvtnorm## Loading required package: modeltools## Loading required package: stats4## Loading required package: strucchange## Warning: package 'strucchange' was built under R version 4.0.5## Loading required package: zoo## Warning: package 'zoo' was built under R version 4.0.5##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numeric## Loading required package: sandwich## Warning: package 'sandwich' was built under R version 4.0.5# Datos de la Flota de Taxis de la ciudad de Madrid.
taxiFlota<-read.csv("http://www.diegocalvo.es/wp-content/uploads/2019/11/taxiFlota.csv",sep = ";",header=TRUE)
head(taxiFlota) # Observamos la cabecera## Código Matrícula Fecha.Matriculación Marca Modelo Tipo Variante
## 1 1198109 0800GZC 18/10/2010 CHEVROLET EPICA KLAL LV3/134
## 2 1196804 7686GYS 23/09/2010 CHEVROLET EPICA KLAL LV1/111
## 3 1182347 5440GTD 02/02/2010 CHEVROLET EPICA KLAL LV3/134
## 4 1189908 3259GWN 21/05/2010 CHEVROLET EPICA KLAL LV3/134
## 5 1180158 9107GSN 29/12/2009 CHEVROLET EPICA KLAL LV3/134
## 6 1194793 2463GYJ 18/08/2010 CHEVROLET EPICA KLAL LV3/134
## Clasificación.medioambiental Combustible Cilindrada Potencia
## 1 B DIESEL 1991 110
## 2 C GASOLINA TRANSFORMADO GLP 1993 105
## 3 B DIESEL 1991 110
## 4 B DIESEL 1991 110
## 5 B DIESEL 1991 110
## 6 B DIESEL 1991 110
## Número.de.Plazas Fecha.inicio.de.prestación.del.servicio.de.taxi Eurotaxi
## 1 5 25/10/2010 NO
## 2 5 04/10/2010 NO
## 3 5 04/02/2010 NO
## 4 5 24/05/2010 NO
## 5 5 04/01/2010 NO
## 6 5 19/08/2010 NO
## Régimen.Especial.de.Eurotaxi Fecha.inicio.Régimen.Especial.Eurotaxi
## 1 NO
## 2 NO
## 3 NO
## 4 NO
## 5 NO
## 6 NO
## Fecha.fin.Régimen.Especial.Eurotaxi Fecha
## 1 30/07/2018
## 2 30/07/2018
## 3 30/07/2018
## 4 30/07/2018
## 5 30/07/2018
## 6 30/07/2018Fase 3: Estudio de datos
Preparación y eliminación de filas incompletas
#Utilizamos la funcion summary() para ver qué datos tenemos
summary(taxiFlota)## Código Matrícula Fecha.Matriculación Marca
## Min. : 550160 Length:46918 Length:46918 Length:46918
## 1st Qu.:1288351 Class :character Class :character Class :character
## Median :1351791 Mode :character Mode :character Mode :character
## Mean :1356890
## 3rd Qu.:1438629
## Max. :1524506
##
## Modelo Tipo Variante
## Length:46918 Length:46918 Length:46918
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
##
##
##
## Clasificación.medioambiental Combustible Cilindrada Potencia
## Length:46918 Length:46918 Min. : 0 Min. : 0
## Class :character Class :character 1st Qu.:1598 1st Qu.: 73
## Mode :character Mode :character Median :1598 Median : 77
## Mean :1684 Mean : 79
## 3rd Qu.:1798 3rd Qu.: 85
## Max. :3498 Max. :193
## NA's :5
## Número.de.Plazas Fecha.inicio.de.prestación.del.servicio.de.taxi
## Length:46918 Length:46918
## Class :character Class :character
## Mode :character Mode :character
##
##
##
##
## Eurotaxi Régimen.Especial.de.Eurotaxi
## Length:46918 Length:46918
## Class :character Class :character
## Mode :character Mode :character
##
##
##
##
## Fecha.inicio.Régimen.Especial.Eurotaxi Fecha.fin.Régimen.Especial.Eurotaxi
## Length:46918 Length:46918
## Class :character Class :character
## Mode :character Mode :character
##
##
##
##
## Fecha
## Length:46918
## Class :character
## Mode :character
##
##
##
## Eliminación de nulos
#Contamos número de nulos por columna
sapply(taxiFlota, function(x) sum(is.na(x))) ## Código
## 0
## Matrícula
## 0
## Fecha.Matriculación
## 0
## Marca
## 0
## Modelo
## 0
## Tipo
## 0
## Variante
## 0
## Clasificación.medioambiental
## 0
## Combustible
## 0
## Cilindrada
## 0
## Potencia
## 5
## Número.de.Plazas
## 0
## Fecha.inicio.de.prestación.del.servicio.de.taxi
## 0
## Eurotaxi
## 0
## Régimen.Especial.de.Eurotaxi
## 0
## Fecha.inicio.Régimen.Especial.Eurotaxi
## 0
## Fecha.fin.Régimen.Especial.Eurotaxi
## 0
## Fecha
## 0#Borramos todas las filas con nulos
taxiFlota <- na.omit(taxiFlota)#Corroboramos el número de nulos por columna
sapply(taxiFlota, function(x) sum(is.na(x))) ## Código
## 0
## Matrícula
## 0
## Fecha.Matriculación
## 0
## Marca
## 0
## Modelo
## 0
## Tipo
## 0
## Variante
## 0
## Clasificación.medioambiental
## 0
## Combustible
## 0
## Cilindrada
## 0
## Potencia
## 0
## Número.de.Plazas
## 0
## Fecha.inicio.de.prestación.del.servicio.de.taxi
## 0
## Eurotaxi
## 0
## Régimen.Especial.de.Eurotaxi
## 0
## Fecha.inicio.Régimen.Especial.Eurotaxi
## 0
## Fecha.fin.Régimen.Especial.Eurotaxi
## 0
## Fecha
## 0Preparación y eliminación de filas duplicadas
Hay duplicados?
#Contamos el número de filas
nrow(taxiFlota) ## [1] 46913#Eliminamos las filas con matrículas repetidas, y me quedo con la carga más actual
MaxFecha_Matricula <- taxiFlota %>% group_by(Matrícula) %>% summarise(Fecha=max(Fecha))#Actualizamos los datos del conjunto sin duplicados
taxiFlota <- merge(x=taxiFlota, y=MaxFecha_Matricula, by=c('Matrícula','Fecha'))#Contamos el nuevo número de filas
nrow(taxiFlota) ## [1] 15967Sección optativa de análisis exploratorio de los datos
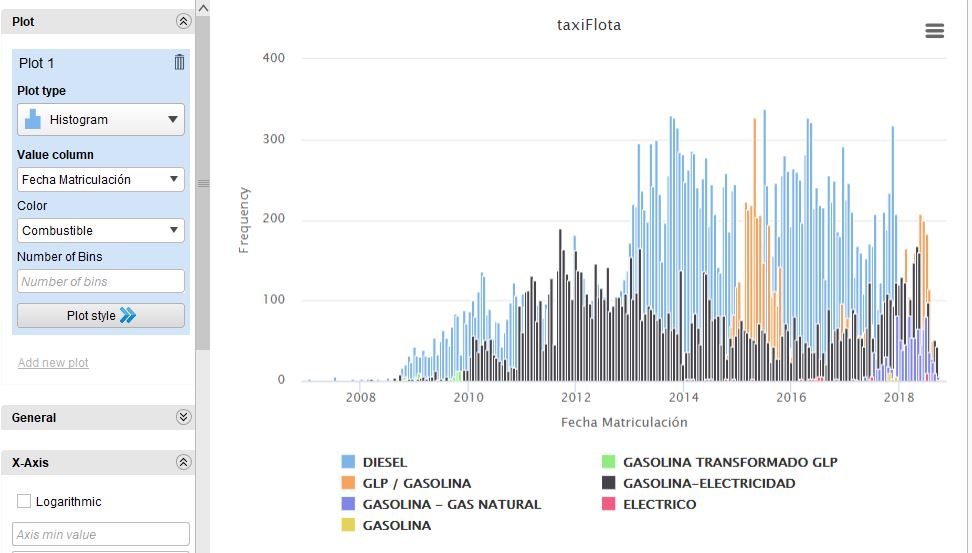
Como aporte me resultó interesante complementar exploraciones en la herramienta de Rapidminer, donde podemos observar en el siguiente histograma una representación de las cantidades o frecuencias con que se matriculaban por fecha, los vehículos según su tipo de combustible diferenciado en colores:
Correlación entre variables mediante un mapa de calor
Pintando el mapa de calor en R
library(ggplot2)## Warning: package 'ggplot2' was built under R version 4.0.5##
## Attaching package: 'ggplot2'## The following object is masked from 'package:randomForest':
##
## marginggplot(taxiFlota, aes(x=Clasificación.medioambiental, y=Marca) ) +
geom_bin2d(bins = 7) +
scale_fill_continuous(type = "viridis") +
theme_bw()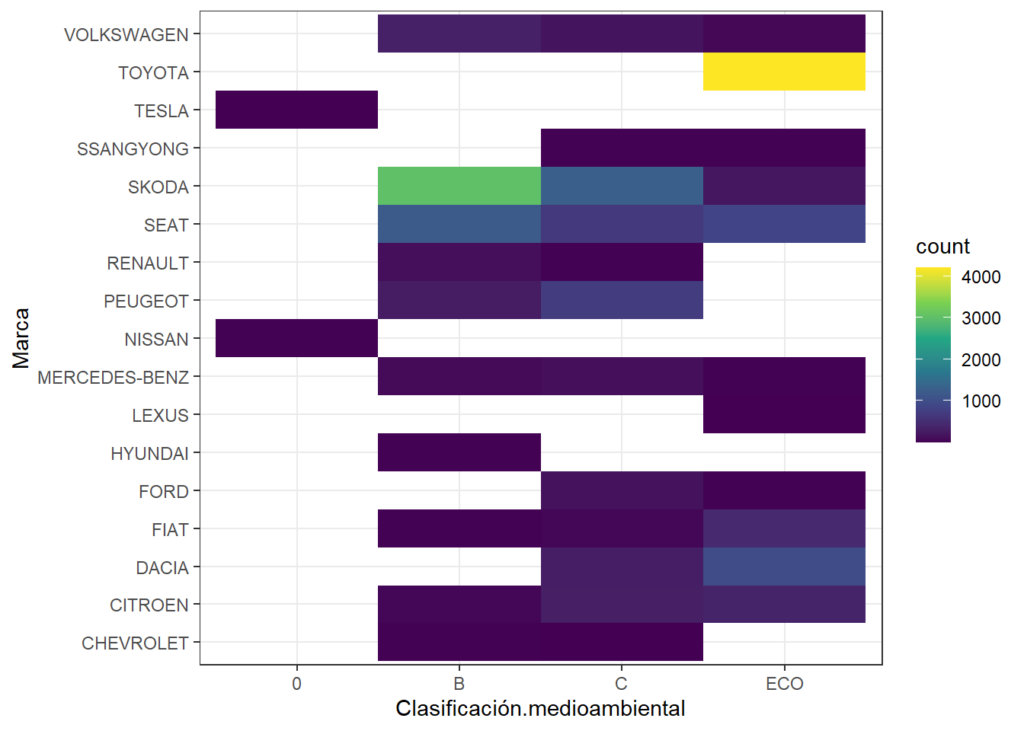
Pintando el mapa de calor en RapidMiner
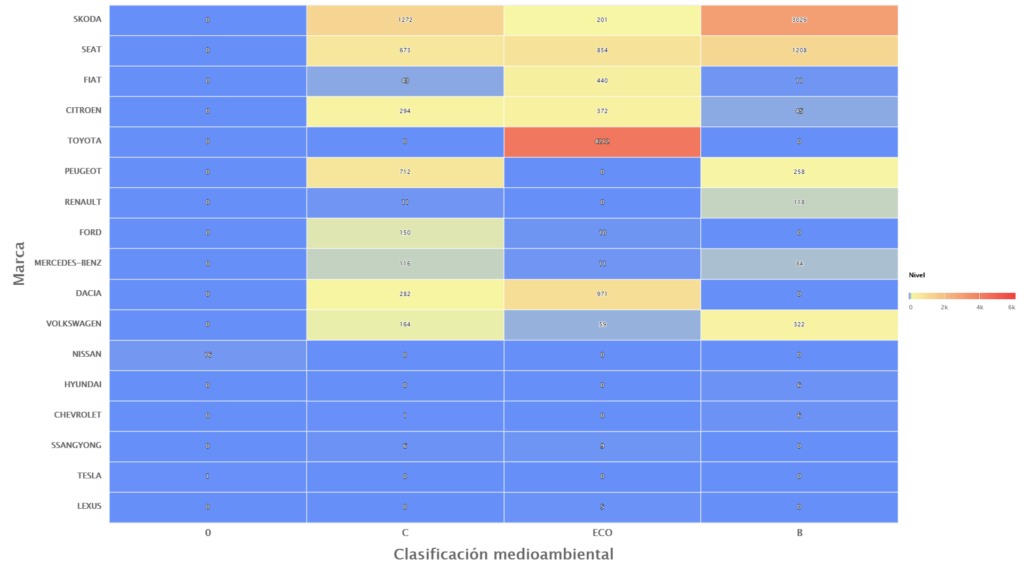
Aquí pudimos obervar a simple vista algo imposible de ver en la planilla de miles de registros. Una distribución de las cantidades de marcas vehículos según su tipo de grado de contaminación, donde afortunadamente la mayoría son los de mayor temperatura en rojo son Toyota y relacionados al tipo ECO.
Distribución de unas variables con respecto a otras
# Distribución de la clasificación medioambiental respecto al combustible
library(ggplot2)
ggplot(taxiFlota, aes(x=Clasificación.medioambiental, y=Combustible) ) +
geom_bin2d(bins = 7) +
scale_fill_continuous(type = "viridis") +
theme_bw()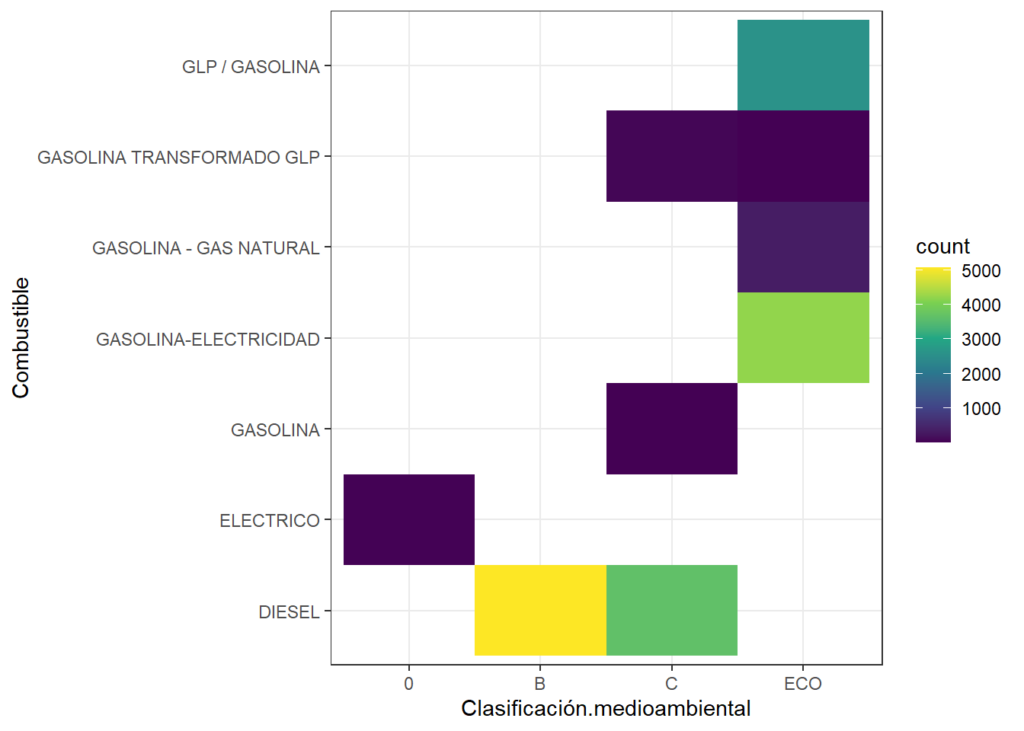
Fase 4: Estudio y comparación de algoritmos de clasificación:
SVM (Support Vector Machine)
Las Máquinas de Vectores de Soporte son modelos capaces de generar clasificaciones o regresiones de datos no lineales a partir de la transformación de los datos de entrada a otros espacios de mayores dimensiones. En el caso de la clasificación, la SVM busca encontrar aquella curva que sea capaz de separar y clasificar los datos de entrenamiento garantizando que la separación entre ésta y ciertas observaciones del conjunto de entrenamiento (los vectores de soporte) sea la mayor posible.
# Preparo los datos
#------------------------------------------------------------------------------
# Fijo una semilla para que los datos aleatorios sean siempre los mismos
set.seed(1234)
#Me quedo ahora con las variables predictoras planteadas por el enunciado
frame2 <- taxiFlota%>%dplyr::select("Clasificación.medioambiental","Combustible","Fecha.Matriculación")
anio <- as.Date(frame2$Fecha.Matriculación, format("%d/%m/%Y"))
frame2$Fecha.Matriculación <- format(anio,"%Y")
str(frame2)## 'data.frame': 15967 obs. of 3 variables:
## $ Clasificación.medioambiental: chr "B" "B" "ECO" "B" ...
## $ Combustible : chr "DIESEL" "DIESEL" "GLP / GASOLINA" "DIESEL" ...
## $ Fecha.Matriculación : chr "2011" "2013" "2017" "2011" ...frame2$Clasificación.medioambiental <- as.factor(frame2$Clasificación.medioambiental)
str(frame2)## 'data.frame': 15967 obs. of 3 variables:
## $ Clasificación.medioambiental: Factor w/ 4 levels "0","B","C","ECO": 2 2 4 2 4 4 4 4 2 2 ...
## $ Combustible : chr "DIESEL" "DIESEL" "GLP / GASOLINA" "DIESEL" ...
## $ Fecha.Matriculación : chr "2011" "2013" "2017" "2011" ...# Partir el conjunto de datos en 2 partes
split <- sample.split(frame2$Clasificación.medioambiental, SplitRatio = 0.75)
# 1) Entrenamiento
training <- subset(frame2, split == TRUE)
# 2) Test
test <- subset(frame2, split == FALSE)
# EXPLORAR DATOS
#------------------------------------------------------------------------------
# Explorar en detalle los datos de entrenamiento
summary(training )## Clasificación.medioambiental Combustible Fecha.Matriculación
## 0 : 11 Length:11975 Length:11975
## B :3813 Class :character Class :character
## C :2793 Mode :character Mode :character
## ECO:5358# Exprorar los datos de test
nrow(training)## [1] 11975nrow(test)## [1] 3992Definiendo el modelo
attach(training) # Permite usar de forma directa las variables
model_svm <- svm(training$Clasificación.medioambiental ~ .,
data = training, # Se indica el conjunto de datos a utilizar
type = 'C-classification', # Indica el tipo de clasificador
scale = FALSE,
cross = 10,
kernel = 'radial') # Indica el tipo de núcleo utilizado
summary(model_svm) # Muestro un resumen del modelo##
## Call:
## svm(formula = training$Clasificación.medioambiental ~ ., data = training,
## type = "C-classification", cross = 10, kernel = "radial", scale = FALSE)
##
##
## Parameters:
## SVM-Type: C-classification
## SVM-Kernel: radial
## cost: 1
##
## Number of Support Vectors: 589
##
## ( 259 50 269 11 )
##
##
## Number of Classes: 4
##
## Levels:
## 0 B C ECO
##
## 10-fold cross-validation on training data:
##
## Total Accuracy: 98.3382
## Single Accuracies:
## 98.24561 98.58097 98.57978 98.08013 98.74687 98.33055 98.49624 97.66277 98.24561 98.41402Predicción del modelo
# Realizar la prediccion
prediction_svm <- predict(model_svm, newdata = test)
# Muestra las predicciones de los test por el identificador del elemento
head(prediction_svm)## 3 10 11 25 32 33
## ECO B C ECO ECO ECO
## Levels: 0 B C ECOEvaluación del modelo con Matriz de confusión
# Definir la matriz de confusión
confusionMatrix_svm <- table(test$Clasificación.medioambiental, prediction_svm)
confusionMatrix_svm## prediction_svm
## 0 B C ECO
## 0 4 0 0 0
## B 0 1232 39 0
## C 0 28 903 0
## ECO 0 0 0 1786# Analizar porcentaje de acierto. Dividir la diagonal entre el total de datos de test
(correctos_svm <- sum(diag(confusionMatrix_svm)) / nrow(test) *100)## [1] 98.32164Conclusión: el algoritmo predice con un alto porcentate del 98% lógicamente dado por la gran relación que existe entre las variables predictoras con la que deseamos estimar ya que por ejemplo está estrechamente relacionado el tipo de combustible con el grado de contaminación.
ARBOLES DE DECISION
Predicción del modelo
model_tree<- rpart(training$Clasificación.medioambiental ~ ., # Se indican las variables
data = training) # Se indica el conjunto de datos a utilizar
# Muestra un resumen del modelo
summary(model_tree)## Call:
## rpart(formula = training$Clasificación.medioambiental ~ ., data = training)
## n= 11975
##
## CP nsplit rel error xerror xstd
## 1 0.5759408 0 1.00000000 1.00000000 0.008223052
## 2 0.3858244 1 0.42405924 0.42405924 0.007004964
## 3 0.0100000 2 0.03823485 0.03823485 0.002378276
##
## Variable importance
## Combustible Fecha.Matriculación
## 53 47
##
## Node number 1: 11975 observations, complexity param=0.5759408
## predicted class=ECO expected loss=0.5525678 P(node) =1
## class counts: 11 3813 2793 5358
## probabilities: 0.001 0.318 0.233 0.447
## left son=2 (6619 obs) right son=3 (5356 obs)
## Primary splits:
## Combustible splits as LLLRRLR, improve=4468.234, (0 missing)
## Fecha.Matriculación splits as LLLLLLLLRRRR, improve=1612.100, (0 missing)
## Surrogate splits:
## Fecha.Matriculación splits as LLLLRRLLRLLR, agree=0.678, adj=0.281, (0 split)
##
## Node number 2: 6619 observations, complexity param=0.3858244
## predicted class=B expected loss=0.4239311 P(node) =0.5527349
## class counts: 11 3813 2793 2
## probabilities: 0.002 0.576 0.422 0.000
## left son=4 (3853 obs) right son=5 (2766 obs)
## Primary splits:
## Fecha.Matriculación splits as LLLLLLLLRRRR, improve=2756.32700, (0 missing)
## Combustible splits as LLR--R-, improve= 31.38274, (0 missing)
## Surrogate splits:
## Combustible splits as LRR--L-, agree=0.585, adj=0.006, (0 split)
##
## Node number 3: 5356 observations
## predicted class=ECO expected loss=0 P(node) =0.4472651
## class counts: 0 0 0 5356
## probabilities: 0.000 0.000 0.000 1.000
##
## Node number 4: 3853 observations
## predicted class=B expected loss=0.03633532 P(node) =0.3217537
## class counts: 0 3713 140 0
## probabilities: 0.000 0.964 0.036 0.000
##
## Node number 5: 2766 observations
## predicted class=C expected loss=0.04085322 P(node) =0.2309812
## class counts: 11 100 2653 2
## probabilities: 0.004 0.036 0.959 0.001# Visualiza el árbol de decision
rpart.plot(model_tree)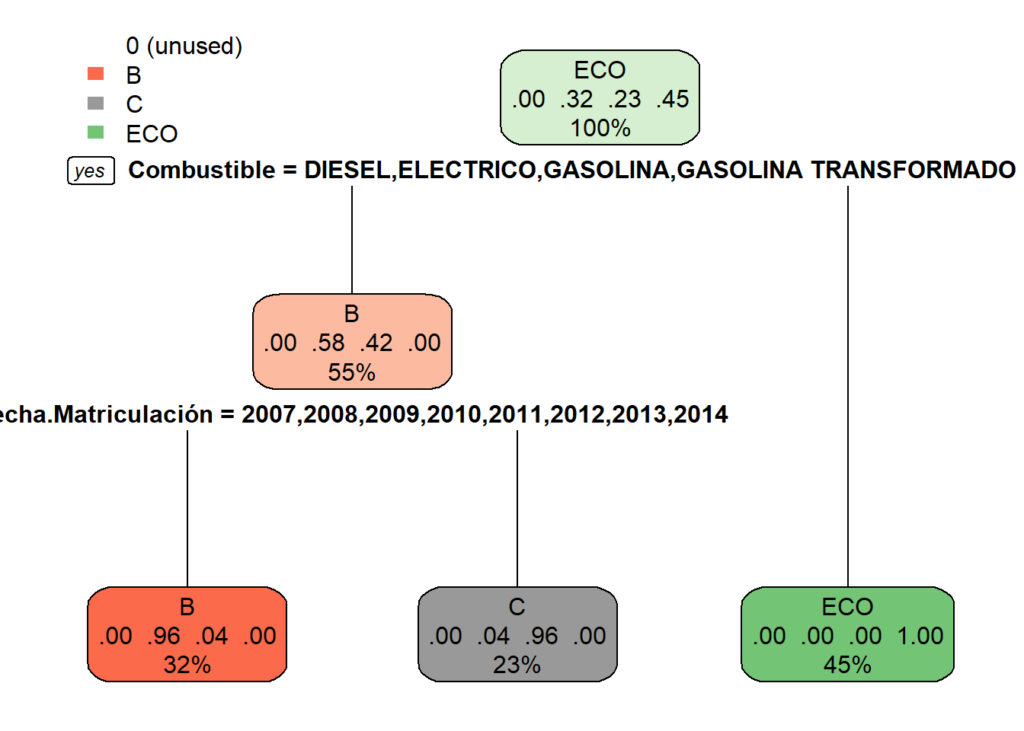
Predicción del modelo
# Realizar la prediccion
prediction_tree <- predict(model_tree, newdata = test, type = "class")
# Muestra las predicciones de los test por el identificador del elemento
head(prediction_tree)## 3 10 11 25 32 33
## ECO B C ECO ECO ECO
## Levels: 0 B C ECOEvaluación del modelo con Matriz de confusión
# Definir la matriz de confusión
confusionMatrix_tree <- table(test$Clasificación.medioambiental, prediction_tree)
confusionMatrix_tree## prediction_tree
## 0 B C ECO
## 0 0 1 3 0
## B 0 1232 39 0
## C 0 37 894 0
## ECO 0 0 0 1786# Analizar porcentaje de acierto. Dividir la diagonal entre el total de datos de test
(correctos_tree <- sum(diag(confusionMatrix_tree)) / nrow(test) *100)## [1] 97.99599BOSQUES ALEATORIOS (Random Forest)
Predicción del modelo
model_ran<- randomForest(training$Clasificación.medioambiental ~ ., # Las variables
data = training,
ntree = 50) # Número de árboles
# Muestra un resumen del modelo
summary(model_ran)## Length Class Mode
## call 4 -none- call
## type 1 -none- character
## predicted 11975 factor numeric
## err.rate 250 -none- numeric
## confusion 20 -none- numeric
## votes 47900 matrix numeric
## oob.times 11975 -none- numeric
## classes 4 -none- character
## importance 2 -none- numeric
## importanceSD 0 -none- NULL
## localImportance 0 -none- NULL
## proximity 0 -none- NULL
## ntree 1 -none- numeric
## mtry 1 -none- numeric
## forest 14 -none- list
## y 11975 factor numeric
## test 0 -none- NULL
## inbag 0 -none- NULL
## terms 3 terms callPredicción del modelo
# Realizar la prediccion
prediction_ran <- predict(model_ran, newdata = test, type = "class")
# Muestra las predicciones de los test por el identificador del elemento
head(prediction_ran)## 3 10 11 25 32 33
## ECO B C ECO ECO ECO
## Levels: 0 B C ECOEvaluación del modelo con Matriz de confusión
# Definir la matriz de confusión
confusionMatrix_ran <- table(test$Clasificación.medioambiental, prediction_ran)
confusionMatrix_ran## prediction_ran
## 0 B C ECO
## 0 3 1 0 0
## B 0 1232 39 0
## C 0 28 902 1
## ECO 0 0 0 1786# Analizar porcentaje de acierto. Dividir la diagonal entre el total de datos de test
(correctos_ran <- sum(diag(confusionMatrix_ran)) / nrow(test) *100)## [1] 98.27154CUANTIFICADOR BAYESIANO INGENUO
Predicción del modelo
model_bay<- naiveBayes(training$Clasificación.medioambiental ~ ., # Las variables
data = training,
laplace = 0) # Deshabilito el suavizado de Laplace
# Muestra un resumen del modelo
summary(model_bay)## Length Class Mode
## apriori 4 table numeric
## tables 2 -none- list
## levels 4 -none- character
## isnumeric 2 -none- logical
## call 4 -none- callPredicción del modelo
# Realizar la prediccion
prediction_bay <- predict(model_bay, newdata = test, type = "class")
# Muestra las predicciones de los test por el identificador del elemento
head(prediction_bay)## [1] ECO B C ECO ECO ECO
## Levels: 0 B C ECOEvaluación del modelo con Matriz de confusión
# Definir la matriz de confusión
confusionMatrix_bay <- table(test$Clasificación.medioambiental, prediction_bay)
confusionMatrix_bay## prediction_bay
## 0 B C ECO
## 0 1 1 0 2
## B 0 1232 39 0
## C 0 30 901 0
## ECO 0 0 0 1786# Analizar porcentaje de acierto. Dividir la diagonal entre el total de datos de test
(correctos_bay <- sum(diag(confusionMatrix_bay)) / nrow(test) *100)## [1] 98.19639Fase 5: Análisis de resultados obtenidos
Existen varias métricas a observar al momento de optar por un modelo, pero para nuestro caso que no son dicotómicas tampoco analizamos la curva ROC, sino que determinaremos el algoritmo de mejor estimación al target en base a la Matriz de confusión. En el apartado previo ya la calculamos para cada caso, y obtuvimos su porcentaje de aciertos.
Desde mi opinión no observé grandes diferencias muy relevantes para discriminar cuál será el mejor algoritmo, por lo que me interesó investigar un poco más y utiliar el aporte de otra herramienta más para comprobar mis calculos: Alteryx
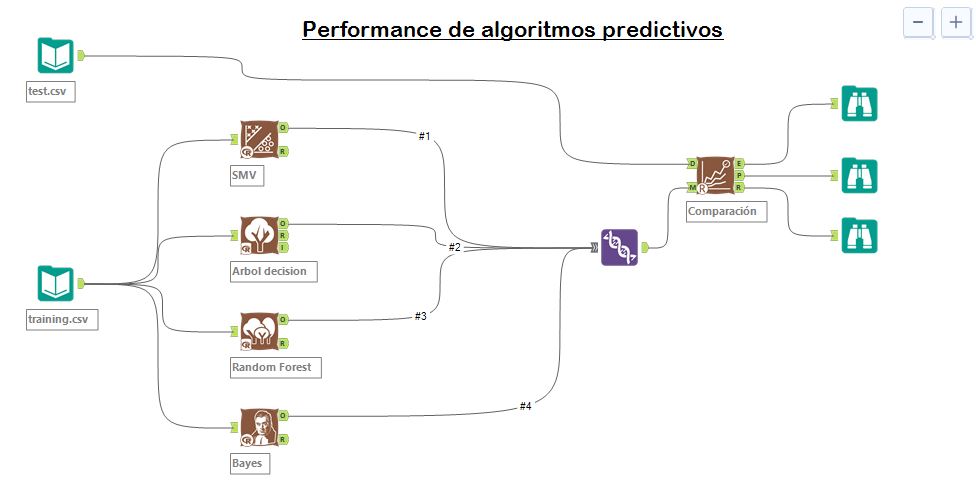
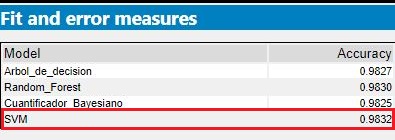
Con la extención de Alterix Predictive, pude modelar los 4 algoritmos cuyos resultados ingresan al procesamiento del bloque comparador del que obtuve el siguiente reporte:
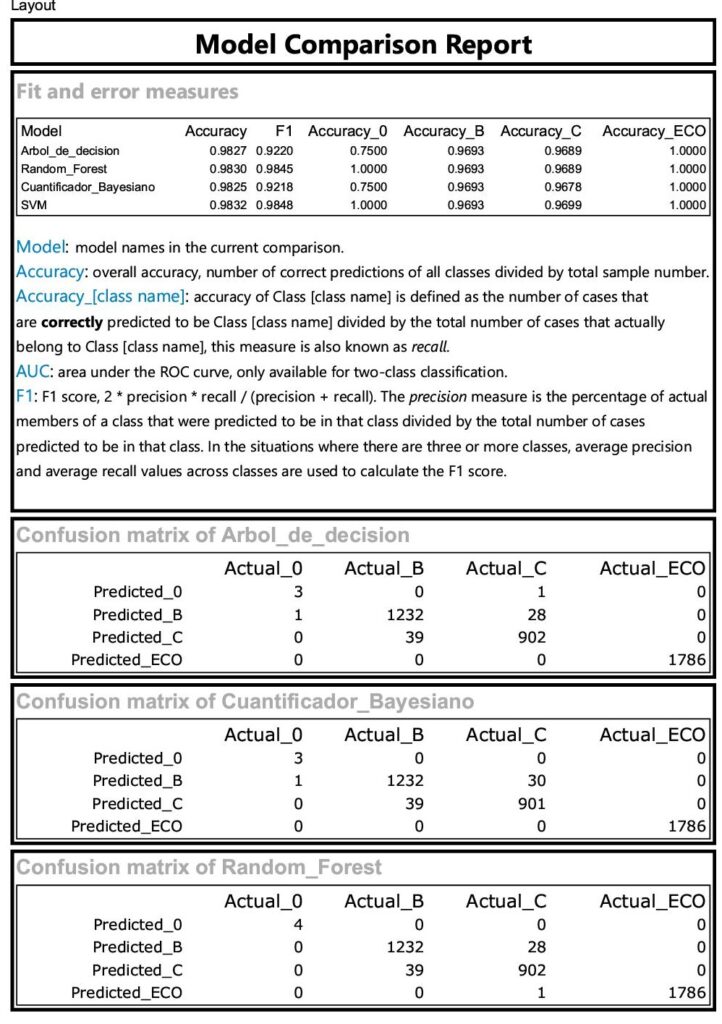
Como conclusiones finales pude comprobar los mismos resultados en los que nuevamente el de mejor performance resultó Support Vector Machine, con un alto acierto del 98,32% con la lógica esperable ya que las variables predictoras como el tipo de combustible están estrechamente relacionadas con el grado de contaminación.